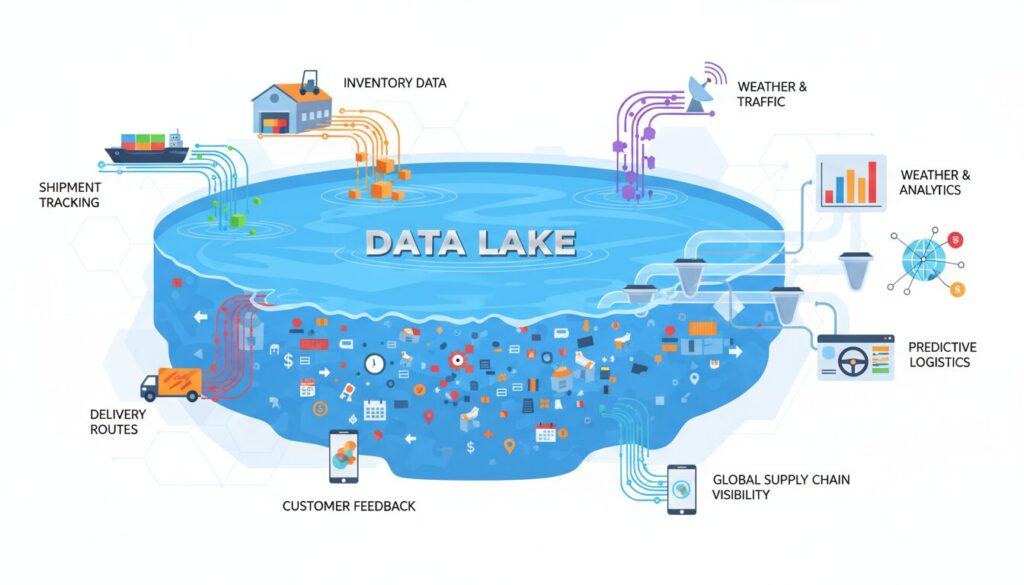
- キーワードの概要:データレイクとは、システムから出力される数値データだけでなく、監視カメラの映像やセンサー情報に至るまで、あらゆる形式のデータをそのままの状態で大量に保存できる次世代のデータ保管庫です。
- 実務への関わり:これまで容量が大きすぎて捨てられていたトラックのGPS軌跡や倉庫内ロボットの稼働データなどを一元管理できます。これにより、AIによる精度の高い需要予測や在庫の最適化が可能となり、迅速な意思決定や業務の自動化など現場の改善に直接役立ちます。
- トレンド/将来予測:単なる保存庫にとどまらず、データウェアハウスの分析機能を併せ持つ「データレイクハウス」への進化が進んでいます。2024年・2026年問題などの業界課題を乗り越えるため、データ駆動型の業務改革を支える必須インフラとして導入がさらに加速する見込みです。
物流業界において、庫内のピッキング実績から、配送トラックのGPS軌跡、さらには倉庫内を縦横無尽に走り回るAGV(無人搬送車)のセンサー情報に至るまで、日々生み出されるデータは爆発的な増加の一途を辿っています。しかし、多くの企業においてこれらのデータは各システムの奥底に死蔵されるか、あるいは「容量が大きすぎる」という理由で破棄され、真の価値を発揮していないのが実態です。こうした多種多様かつ膨大なデータを一元的に集約し、高度なAI予測や自動化といった真のビッグデータ 活用を実現するための次世代基盤として、現在「データレイク」が不可欠な存在となっています。
本記事では、物流DXの成否を握るデータレイクの概念から、既存のデータウェアハウス(DWH)との明確な違い、最大の落とし穴である「データスワンプ」の回避策、そして具体的な構築ステップや組織的課題の克服に至るまで、物流現場の超・実務視点から極めて詳細に解説します。
- データレイクとは?ビッグデータ活用を支える次世代のデータ基盤
- データレイクの基本定義と仕組み(スキーマオンリード)
- ビッグデータ活用やDX推進においてなぜ重要なのか
- 【徹底比較】データレイク・データウェアハウス(DWH)・データマートの違い
- 役割とアーキテクチャ構造の決定的な違い
- 取り扱う「データ形式」と「処理アプローチ」の違い
- 利用目的と想定ユーザーによる使い分けと組織のサイロ化問題
- データレイクを導入する4つのメリットと重要KPIの創出
- 膨大な非構造化データの安価な保存(スケーラビリティ)
- データサイロの解消と全社的なデータ統合
- AI・機械学習、予測分析への高い親和性
- 迅速な意思決定を支えるアジリティとBCP(事業継続)の強化
- 最大の落とし穴「データスワンプ」の回避とガバナンス
- データスワンプ(データの沼)化する原因と致命的リスク
- データガバナンスとライフサイクル管理の徹底
- セキュリティ対策と適切なアクセス制御の実装
- データレイクの最新トレンドとソリューション選定基準
- 次世代アーキテクチャ「データレイクハウス」への進化
- AWS・Azureなどクラウド型ソリューションの活用と特徴
- 自社のビジネス課題に合わせたプラットフォーム選定のポイント
- 【実践】データレイク構築のステップと「2026年問題」を見据えたDX実装
- データレイク構築を成功に導く4つのステップ
- 【SCM特化】物流・サプライチェーンにおける非構造化データの統合
- 2024年・2026年問題に向けたデータ駆動型の業務改革とチェンジマネジメント
データレイクとは?ビッグデータ活用を支える次世代のデータ基盤
データレイクの基本定義と仕組み(スキーマオンリード)
データレイク(Data Lake)とは、その名の通り「データの湖」を意味します。WMS(倉庫管理システム)やTMS(輸配送管理システム)から出力される売上・在庫といった「構造化データ」だけでなく、庫内監視カメラの画像、ハンディターミナルの生ログ、トラックのドラレコ映像といった非構造化データ、さらにはJSONやXML形式でやり取りされる「半構造化データ」を、加工することなく「そのままの形式(ローデータ)」で無尽蔵に保存できるスケーラブルなストレージ基盤を指します。
ここで技術的かつ実務的に極めて重要なのが、スキーマオンリード(読み取り時スキーマ設定)というアーキテクチャ上のアプローチです。従来のリレーショナルデータベースやDWHでは、データを蓄積する前に「どのようなテーブル構造で、どう使うか」を事前に定義してデータの形を整える必要(スキーマオンライト)がありました。しかしデータレイクでは、「とりあえず生のまま放り込み、後から分析やAI学習で必要になった瞬間に、データの読み出し方(スキーマ)を定義する」というアプローチをとります。
物流現場の超・実務視点から見ると、この恩恵は計り知れません。以下に現場での具体的な運用例を挙げます。
- あらゆるデータを捨てずに溜める: 例えば、最新のAGVに搭載されたLiDARセンサーが取得する障害物検知の生データや、ピッキングカートの秒単位の移動ログなどは、従来「容量が大きすぎる」「現時点ではすぐには使わない」という理由で破棄されてきました。しかし、クラウド型のデータレイクに安価にローデータを蓄積しておくことで、後日「庫内の特定エリアにおける渋滞ボトルネック分析」を行いたくなった際、過去数ヶ月に遡って解析することが可能になります。
- 柔軟な探索的分析の実現: データサイエンティストがAIの需要予測モデルを構築する際、既存のフォーマットに丸められたデータではなく、「気温の変動」「SNSのトレンドデータ」「ドライバーの急ブレーキのログ」といった未加工の特徴量を直接投入し、未知の相関関係を発見することができます。
ビッグデータ活用やDX推進においてなぜ重要なのか
なぜ今、物流DXにおいてデータレイクが最重要課題として挙げられるのでしょうか。それは、物流領域が抱える複雑な課題の解決には「サイロ化されたシステムの枠を超えたデータの掛け合わせ」が絶対に不可欠だからです。
例えば「トラックのバース待機問題(荷待ち時間の削減)」を解決するためには、予約システムのデータ(構造化)と、実際の入場ゲートの監視カメラ映像(非構造化データ)、さらには周辺道路のリアルタイムな渋滞情報や気象データなどを統合してAIに学習させ、動的な到着予測モデルを構築する必要があります。既存のDWHが「きれいに成形された定型分析用データの保管庫」であるのに対し、データレイクは「未知の洞察を得るための、あらゆる生データの源泉(シングル・ソース・オブ・トゥルース:信頼できる唯一の情報源の素)」として機能します。
データレイクは、現場から湧き出る膨大な生データを受け止める「ファーストレシーバー」としての役割を持ちます。溜め込んだデータを必要に応じてクレンジングしてDWHへ送り込み、最終的に現場のビジネスユーザーが使いやすいデータマートへと提供する、データパイプライン全体の出発点なのです。単なる「大容量ストレージ」と侮るのではなく、今後の高度なAI活用や自動化を支える“地盤”として、データレイクの概念を正確に把握しておくことがDX推進の第一歩となります。
【徹底比較】データレイク・データウェアハウス(DWH)・データマートの違い
物流現場のDX化が急務となる中、各拠点のWMSやTMS、さらにはマテリアルハンドリング機器から日々膨大なデータが生成されています。しかし、「とにかくデータを一箇所に集める」という号令のもと、行き当たりばったりで分析基盤の構築を進めると、システムはすぐに破綻し、誰も使わないシステムが完成します。ここで重要になるのが、データレイクと、既存のデータウェアハウス(DWH)、データマートの明確な「データウェアハウス 違い」を理解し、プロジェクトのフェーズや利用者に合わせて適切に使い分けることです。
役割とアーキテクチャ構造の決定的な違い
これら3つのデータ基盤は、物流サプライチェーンにおける「データの保管庫・加工場・販売所」に例えることができます。アーキテクチャ上の役割は以下の通りです。
- データレイク(巨大な保管庫):形式を問わず、システムから発生した「生データ」をそのまま保管する巨大なプールです。あらゆる非構造化データを格納し、未知の分析ニーズに備えます。
- DWH(中央加工場):生データをクレンジング・統合し、全社横断的な分析ができるよう構造化(テーブル化)して保管するデータベースです。複数拠点の異なるWMSフォーマットを共通言語に変換し、全社の在庫回転率や配車効率を正確に比較・分析するための基盤となります。
- データマート(専門販売所):DWHから、特定の部門や用途(例:「関東エリアの当日のピッキング進捗管理」「特定荷主向けの出荷実績」など)に必要なデータだけを切り出し、現場のビジネス担当者がすぐに使えるように最適化した小規模データベースです。
| 比較項目 | データレイク | データウェアハウス(DWH) | データマート |
|---|---|---|---|
| データの状態 | 生データ(構造化・半構造化・非構造化データすべて) | 加工済・構造化データ(テーブル形式にクレンジング済) | 高度に加工済・集計済データ(特定業務向けに最適化) |
| 利用目的 | 機械学習、AI需要予測、未知のインサイト発掘、生ログの長期保存 | 全社横断的な定型分析、KPIの予実管理、全社BIツール向けの中間基盤 | 現場業務の迅速な意思決定、日次・時間次のダッシュボード表示 |
| 想定ユーザー | データサイエンティスト、データエンジニア | 経営層、DX推進責任者、ビジネスアナリスト | 現場のセンター長、配車担当者、特定の荷主担当部門 |
| 柔軟性とコスト | 極めて柔軟。ストレージコストは非常に安価(クラウドのオブジェクトストレージ等) | 事前のスキーマ設計が必要で柔軟性は低い。処理・ストレージコストは高め | 目的特化型のため他用途への転用不可。構築コストは比較的安価 |
取り扱う「データ形式」と「処理アプローチ」の違い
物流業界のデータ活用において、情報システム部門の最大の壁となるのが「データ形式の不統一」です。M&Aで統合した別会社のシステムデータや、荷主ごとに異なるEDIデータを無理やりDWHに直接統合しようとすると、格納前にフォーマットを変換するETL(データ抽出・変換・書き出し)処理の開発が異常なほど複雑化し、いわゆる「ETL地獄」に陥ります。
前述の通り、データレイクはスキーマオンリードのアプローチをとるため、まずは安価なオブジェクトストレージに生データを「とりあえず放り込む」ことで、システム連携の初期ハードルを劇的に下げることができます。これにより、データ収集フェーズのスピードが飛躍的に向上し、IT部門の開発リソースを「データの加工・分析」というより価値の高い業務に振り向けることが可能になります。
利用目的と想定ユーザーによる使い分けと組織のサイロ化問題
「誰が、何のためにデータを使うのか」によってアクセスすべき基盤は厳密に区別されなければなりません。現場のセンター長や配車マンが直接データレイクの生データをSQLで叩くことはありません。彼らはデータマートに接続されたBIツール(TableauやPower BIなど)を利用し、「今日の出荷遅延リスク」や「トラックの待機時間」といった、直近のオペレーション改善に必要な数値を瞬時に確認します。現場のBIツールが遅い(クエリがタイムアウトする)というクレームの多くは、データマートを適切に切り出さず、重いDWHやデータレイクに直接クエリを投げていることが原因です。
一方で、物流現場のデータ活用でよく起こる組織的な悲劇が「データマートの無秩序な乱立」です。全社的なDWHの構築をすっ飛ばし、各拠点の要望に応じてIT部門が場当たり的にデータマートを作り続けた結果、「関東センターと関西センターで、”出荷完了”の定義と在庫数が合わない」「経営会議に提出されるレポートの数値が部門ごとに違う」といったサイロ化を招きます。「生データを集める柔軟なレイク」「全社で真実を一つにする堅牢なDWH」「現場が使い倒す俊敏なマート」という3層構造のガバナンスを意識することが、真の物流DXを実現するカギとなります。
データレイクを導入する4つのメリットと重要KPIの創出
物流企業のDX推進において、従来型のDWHだけでは太刀打ちできない壁が存在します。それは「現場から湧き出るデータの質と量の劇的な変化」です。ここでは経営層やIT部門が享受できるデータレイク特有のビジネス価値と、それがどのような実務KPIの向上に寄与するのかを4つの視点から解説します。
膨大な非構造化データの安価な保存(スケーラビリティ)
物流センターや輸配送の現場では、日々膨大な非構造化データが生み出されています。トラックのドライブレコーダー映像、庫内監視カメラの画像、フォークリフトのIoTセンサーから送られる秒単位の温度・振動データなどです。これらを従来のDWHに保存しようとすると、ストレージ単価が高いため莫大なコストがのしかかります。
データレイクは、容量無制限のクラウド・オブジェクトストレージを活用するため、ペタバイト級のデータであっても極めて安価に保存できるコストメリットがあります。例えば、AWSが提供するAmazon S3などを利用すれば、ハードウェアの調達を待たずに数分で容量を拡張できます。将来の高度な分析を見据え、「今は何に使うか明確ではないが、いつかAIの学習データになるかもしれない現場の生データ」をコストを気にせずストックできることは、データ駆動型企業への変革において極めて強力な武器となります。
データサイロの解消と全社的なデータ統合
多くの物流企業が長年苦しんでいるのが、「WMS」「TMS」「OMS(受注管理システム)」がベンダーごとに分断されているサイロ化の問題です。データレイクは、ファイルフォーマットを問わずあらゆるシステムからデータを「生のまま」一元的に集約できるため、全社横断的なデータ統合のハブとして機能します。
これにより、これまで測定が困難だった「サプライチェーン全体を通したリードタイム」や「エンドツーエンドの物流コスト」といった重要KPIを正確に可視化することが可能になります。例えば、「荷主からの受注(OMS)」から「倉庫でのピッキング完了(WMS)」、そして「最終顧客への配送完了(TMS)」までの各プロセスのタイムスタンプをデータレイク上で紐付けることで、ボトルネックがどこにあるのかをデータドリブンに特定できるようになります。
AI・機械学習、予測分析への高い親和性
物流領域におけるDXの最前線は、AIによる高精度な需要予測(物量予測)や、機械学習を用いた動的な配車ルートの最適化、さらには庫内作業員の最適配置です。これらの高度な予測モデルの構築には、DWHに格納された「きれいに丸められた集計データ」だけでは不十分です。
データレイクは、データサイエンティストや機械学習エンジニアが必要な生データ(天候データ、渋滞の生ログ、ドライバーの微細なブレーキ操作履歴などの特徴量)へダイレクトにアクセスし、自由な切り口でモデルをトレーニングするための最適な基盤となります。これにより、「待機時間の削減率」「積載率の向上」「ピッキング生産性(行/時)の向上」といった、物流リソースの最適化に直結するKPIを劇的に改善するAIソリューションを生み出す土壌が形成されます。
迅速な意思決定を支えるアジリティとBCP(事業継続)の強化
物流の現場は変化が激しく、荷主の要件変更に伴ってWMSの管理項目が突然追加されたり、新たな自動搬送ロボット(AMR)のログ連携が必要になったりすることは日常茶飯事です。データを保存する前に構造を定義しなければならないDWHでは、現場の変更のたびにデータ連携処理の開発・改修が走り、IT部門がボトルネックとなります。一方、データレイクはスキーマオンリードの性質を持つため、現場のシステム変更に対する影響を最小限に抑え、アジリティ(俊敏性)を劇的に向上させます。
さらに実務上で極めて重要なのが、障害時のバックアップ(BCP対策)としての役割です。現場で最も恐ろしいのは、出荷のピーク時にWMSが突然停止することです。この際、各ハンディターミナルやマテハン機器からの動作ログ(APIの生リクエストなど)を並行してデータレイクに直接ストリーミング保存するアーキテクチャを構築していれば、システム復旧時に「どこまでピッキングが完了していたか」の証跡を生ログから抽出し、欠損データを即座に補完できます。これにより、システムのRTO(目標復旧時間)およびRPO(目標復旧時点)を大幅に短縮し、物流を止めない強靭なインフラを構築することが可能になります。
最大の落とし穴「データスワンプ」の回避とガバナンス
データレイクはあらゆる情報を集約できる「夢の箱」のように語られがちです。しかし、事前の設計や運用ルールなしに導入すると、待ち受けているのはデータが無秩序に散乱する「データスワンプ(データの沼)」という最悪の結末です。ここでは、データ基盤を真の資産として機能させるための、超・実務的な運用論とガバナンスについて解説します。
データスワンプ(データの沼)化する原因と致命的リスク
データレイクの最大のメリットである「スキーマオンリード」は、裏を返せば「整理整頓の先送り」でもあります。物流の現場において、WMSのトランザクションログ、TMSのGPSトラッキング、AGVの稼働センサーデータなどを「とりあえず」放り込み続けると、たちまちデータスワンプ化を引き起こします。
明確なルールなく蓄積されたデータは、いざ本格的な分析を推進しようとしても「どこに・何の・いつの」データがあるのか誰も把握できません。実務において最も恐ろしいのは、データ品質が担保されていない状態のデータを現場のレポートに反映してしまうことです。「在庫数が合わない」「昨日の出荷実績がシステム間で異なる」といった事態が頻発すれば、現場はデータ基盤への信頼を完全に失い、二度とシステムを使ってくれなくなります。
データガバナンスとライフサイクル管理の徹底
データスワンプを回避するためには、強力なデータガバナンスの策定が不可欠です。具体的には、「どの拠点の(拠点ID)」「どのベンダーのシステムから出力された(システムコード)」「いつのデータか(タイムスタンプ)」といったメタデータ(データに関する説明書き)を必ずタグ付けして格納するルールをシステム側で強制します。また、組織的な対応として「データスチュワード(データ品質とライフサイクルを管理する責任者)」を任命し、データの鮮度や完全性を継続的に監視する体制を構築することが推奨されます。
さらに、物流現場のデータは「鮮度」によって価値が劇的に変化するため、ストレージの階層化(ライフサイクル管理)がコスト最適化の鍵を握ります。
| データ階層 | 対象データの具体例(物流現場) | アクセス頻度・要件 | 格納先・活用アプローチ |
|---|---|---|---|
| ホットデータ | 当日のWMS稼働ログ、AGVのリアルタイムセンサーデータ | 数ミリ秒〜数秒での超高速アクセス。障害検知・リカバリに直結。 | 高速ストレージ / 一部は特定の目的ごとにデータマート化しBIで監視 |
| ウォームデータ | 過去1ヶ月の配車実績、ピッキングエラー時の検品画像データ | 週次・月次のKPI分析。数分程度のクエリレスポンスで許容可能。 | 標準オブジェクトストレージ / 分析ツールからの直接クエリ実行 |
| コールドデータ | 1年以上前の輸配送履歴、法定保存要件を満たすための伝票データ | 滅多にアクセスしない。コンプライアンス対応や監査時にのみ使用。 | アーカイブストレージ(検索速度よりも保管コストの最小化を最優先) |
セキュリティ対策と適切なアクセス制御の実装
物流データには、荷主企業の機密情報や、エンドユーザーの個人情報(配送先住所、氏名、電話番号など)が大量に含まれています。そのため、クラウド上にデータレイクを構築する際には、堅牢なセキュリティ対策と細やかなアクセス制御が必須要件となります。
現場導入時に情報システム部がよく直面する課題は、「現場の作業長にはWMSのダッシュボードを見せたいが、個人情報には触れさせたくない」「本社のデータエンジニアには分析用に全件データへのアクセスを許可したい」という権限管理のトレードオフです。これを解決するためには、以下のアクセス制御を実装します。
- ロールベースのアクセス制御(RBAC): 本社のデータアナリスト、各物流センターの拠点長、現場のパートリーダーなど、役割(ロール)に応じて閲覧可能なデータの範囲を厳密に制限します。
- カラム(列)レベルのマスキング処理: 分析に不要な個人情報は、データレイクからデータマートへ抽出する段階、あるいはクエリ実行時に動的マスキング(伏せ字化・暗号化)を施し、現場端末に生データが表示されない仕組みを構築します。
- 監査ログの継続的な監視: 「誰が、いつ、どの個人情報データにアクセスしたか」を常にトラッキングし、深夜帯の不自然な大量ダウンロードや異常なアクセス頻度を自動検知してアラートを発報する体制を整えます。
データレイクの最新トレンドとソリューション選定基準
物流DXが加速する中、データレイクの構築は「とりあえずシステムログを溜める」という初期段階から、「いかに現場の意思決定を高速化し、止まらない物流を構築するか」という実運用フェーズへ移行しています。ここでは最新のアーキテクチャトレンドと、プラットフォーム選定の指針を解説します。
次世代アーキテクチャ「データレイクハウス」への進化
従来のデータレイクは、非構造化データを安価に大量保存できるメリットがあった反面、データ品質の担保やトランザクション処理(データの更新・削除などの整合性維持)が苦手という弱点がありました。これがデータスワンプを生み出す一因でもありました。この弱点を克服し、データレイクの「柔軟性・スケーラビリティ」と、DWHの「堅牢なデータ管理能力・高速処理」を融合させた次世代アーキテクチャがデータレイクハウスです。
データレイクハウスは、オブジェクトストレージ上に構築されながらも、ACIDトランザクション(データの確実な書き込みや更新を保証する仕組み)をサポートします。物流現場において、この進化は劇的な変化をもたらします。例えば、WMSから発生するリアルタイムの在庫トランザクションデータ(更新が頻繁に発生するデータ)と、過去数年分の天候データなどの非構造化データを、別のシステムにコピーすることなく同一基盤上で統合・分析することが可能になります。これにより、鮮度の高いダッシュボードを圧倒的な低遅延で現場に提供できるようになります。
AWS・Azureなどクラウド型ソリューションの活用と特徴
現在、データ分析基盤の構築において主流となっているのがパブリッククラウドのマネージドサービスです。代表的な2大プラットフォームの特徴を、物流実務の視点で比較します。
| クラウドベンダー | 代表的なサービス構成 | 物流現場における活用メリットと運用上の特徴 |
|---|---|---|
| AWS (Amazon Web Services) | Amazon S3, AWS Lake Formation, Amazon Athena, AWS Glue | 納品書PDFや音声メモ等の非構造化データをとりあえずS3に放り込み、Athenaを用いてスキーマオンリードで柔軟にSQLクエリを叩ける点が秀逸。Lake Formationによる緻密なアクセス権限(カラムレベルのマスキング等)の集中管理が強力。 |
| Microsoft Azure | Azure Data Lake Storage (ADLS), Azure Synapse Analytics | Windows系OSや、既存のオンプレミスSQL Server(基幹系システム)との親和性が極めて高い。全社的なActive Directoryのセキュリティポリシーをそのまま適用しやすく、エンタープライズの堅牢性と統合管理に優れる。 |
自社のビジネス課題に合わせたプラットフォーム選定のポイント
物流企業がソリューションを選定する際、単なるITカタログのスペック比較は無意味です。「現場のどの課題を解決し、トラブル時にどう運用するか」を起点に、以下の3つのポイントを厳しく評価してください。
- 非構造化データの取り扱いとスキーマオンリードの容易さ: 現場では、手書き日報のスキャンデータやパレットの荷姿画像など、形式が定まらないデータが日々大量に発生します。これらを生データのまま蓄積し、分析する瞬間に構造を定義する機能が、現場のデータエンジニアにとって直感的に扱えるかを検証します。
- データガバナンスと自動化機能: メタデータの自動付与やデータカタログ機能が貧弱なツールを選ぶと、必ずデータスワンプに陥ります。「誰が・いつ・どのWMSから抽出したデータか」を自動追跡(データリネージ)できるソリューションが必須です。
- ベンダーロックインの回避と拡張性: 特定のクラウドベンダーの独自技術に依存しすぎると、将来的なシステム移行やマルチクラウド運用が困難になります。オープンソースのフォーマット(ParquetやIcebergなど)をサポートしているかを確認し、将来の拡張性を担保します。
【実践】データレイク構築のステップと「2026年問題」を見据えたDX実装
物流業界において、膨大なデータは「とりあえず保管する」段階から「切迫する経営課題を即座に解決する」段階へと完全に移行しました。ここでは、データレイクを実務に落とし込み、深刻化する物流リソース不足に立ち向かうための実践的なアプローチを解説します。
データレイク構築を成功に導く4つのステップ
データレイクの構築は、ただシステムへデータを流し込めばよいわけではありません。以下の4ステップに沿った厳格なプロセス管理が不可欠です。
- 収集(Ingestion): WMSやTMSのトランザクションログ、フォークリフトのIoTセンサーデータ、ドラレコ映像まで、あらゆる形式のデータを生フォーマットのまま取り込みます。リアルタイムストリーミングとバッチ処理を要件に応じて使い分けます。
- 保存(Storage): 安価なクラウドオブジェクトストレージを活用し、ペタバイト級の容量に対して低コストで無限の拡張性を確保します。ここでメタデータの付与を徹底します。
- 処理・分析(Processing & Analysis): データを読み出す際に初めて構造を定義するスキーマオンリードのアプローチを採用し、クレンジングや匿名化処理を行います。事前のテーブル設計に縛られず、現場の突発的な分析要件にも柔軟に対応します。
- 活用(Consumption): 抽出・加工したデータを全社DWHへ連携したり、特定部門(配車担当や在庫管理者など)向けに特化したデータマートを生成し、BIツールと連携させて現場の迅速な意思決定を支援します。
【SCM特化】物流・サプライチェーンにおける非構造化データの統合
物流現場における最大のボトルネックは、荷主・倉庫・運送会社間でシステムが分断された「サイロ化」と、従来のRDBでは取り扱いが難しい非構造化データの扱いです。トラックのGPSトラッキングデータ、ドライブレコーダーの映像、ピッキングカートの動線ログ、さらには送り状のOCR画像など、従来は「容量を食うだけ」と捨てられていたこれらのデータにこそ、業務効率化の宝が眠っています。
綺麗に整形された売上や入出荷の実績データはDWHで高速処理し、多様な生データはデータレイクに格納して探索的分析に用いる、あるいは両者を統合したデータレイクハウスを活用することで、サプライチェーン全体(SCM)の最適化を図ります。特定ベンダーのパッケージシステムに依存した閉じたデータ管理から脱却し、自社でデータをコントロールする主権を取り戻すことが、これからの物流企業に求められる姿勢です。
2024年・2026年問題に向けたデータ駆動型の業務改革とチェンジマネジメント
トラックドライバーの時間外労働規制強化による「2024年問題」に続き、労働力人口の絶対的な減少により物流業が構造的限界を迎えると言われる「2026年問題」。この危機を乗り越えるためには、経験と勘に頼ったアナログな管理から、データ基盤を起点とした完全なデータ駆動型オペレーションへのシフトが求められます。
| 業務領域 | 従来の課題(サイロ化・アナログ依存) | データレイク導入後の解決シナリオ |
|---|---|---|
| 配車・輸配送 | 熟練の配車マンの経験に依存。突発的な渋滞や待機時間への対応が後手になり、積載率と稼働率が低下。 | GPSデータ、気象データ、各納品先の過去の荷待ち時間ログ(非構造化データ)を統合し、AIによる動的ルート最適化と精緻な到着時間予測を実現。 |
| 庫内作業管理 | WMSの「処理完了実績」しか見えず、作業遅延の「真の理由(手待ち・機材の渋滞)」がブラックボックス化。 | ビーコン等のセンサーデータによる作業員の動線分析とWMSのタスクデータを掛け合わせ、庫内の渋滞箇所やボトルネックをリアルタイムに検知し、作業割り当てを自動調整。 |
| 需給・在庫予測 | 過去の出荷実績のみで予測を行うため、特売や天候による急激な変動に対応できず、欠品や過剰在庫が発生。 | POSデータ、SNSのトレンドデータ、気象情報などを統合し、高度な機械学習モデルでサプライチェーン全体の在庫配置と補充タイミングを最適化。 |
最後に強調すべきは、どれほど強力なデータレイクを構築したとしても、それを扱う「人」と「組織」が変わらなければ意味がないという事実です。現場の配車マンや庫内作業長が「データを使って自ら業務を改善する」というマインドを持たなければ、DXは絵に描いた餅に終わります。
プラットフォームの技術的な構築と並行して、現場部門へのデータリテラシー教育を推進し、従来のやり方を手放すためのチェンジマネジメント(組織変革)を強力に推し進めること。IT部門と現場が一体となり、データを共通言語として対話する企業文化を醸成することこそが、次世代の物流インフラを構築し、過酷な競争を生き抜くための唯一の道筋となります。
よくある質問(FAQ)
Q. 物流におけるデータレイクとは何ですか?
A. データレイクとは、配送トラックのGPS軌跡やAGVのセンサー情報など、多種多様で膨大な生データをそのまま一元的に集約・保存する次世代のデータ基盤です。各システムに死蔵されがちなデータを活用可能な状態にし、高度なAI予測や自動化といった物流DX(ビッグデータ活用)を実現するために不可欠な存在です。
Q. データレイクとデータウェアハウス(DWH)の違いは何ですか?
A. 最大の違いは「保存するデータ形式」と「利用目的」です。データレイクは非構造化データを含むあらゆる生データをそのまま安価に保存し、主にAI開発や機械学習に用いられます。一方のDWHは、あらかじめ分析しやすいように構造化・加工されたデータを格納し、現場や経営層の業務分析に利用されるという明確な違いがあります。
Q. データレイクを導入するメリットは何ですか?
A. 膨大なデータを安価に保存できる拡張性と、組織内のデータサイロ(孤立)を解消して全社的なデータ統合が図れることです。あらゆるデータを一元管理することでAIや機械学習の導入がスムーズになり、精度の高い予測分析が可能になります。結果として、迅速な意思決定や物流現場の生産性向上、事業継続(BCP)の強化に繋がります。